No. 10: He Can Handle the Pressure Not only has Travis played in three, soon to be four, Super Bowls,
LATEST NEWS


LATEST NEWS

TECHNOLOGY

How to change your IP address, why you’d want to – and when you shouldn’t
Jack Wallen/ZDNET Security and privacy have been hot topics for a long time (and that’s not going to change any

Snap says total watch time on its TikTok competitor increased more than 125%
As part of its Q1 2024 earning release, Snap revealed that total watch time on its TikTok competitor, Spotlight, increased
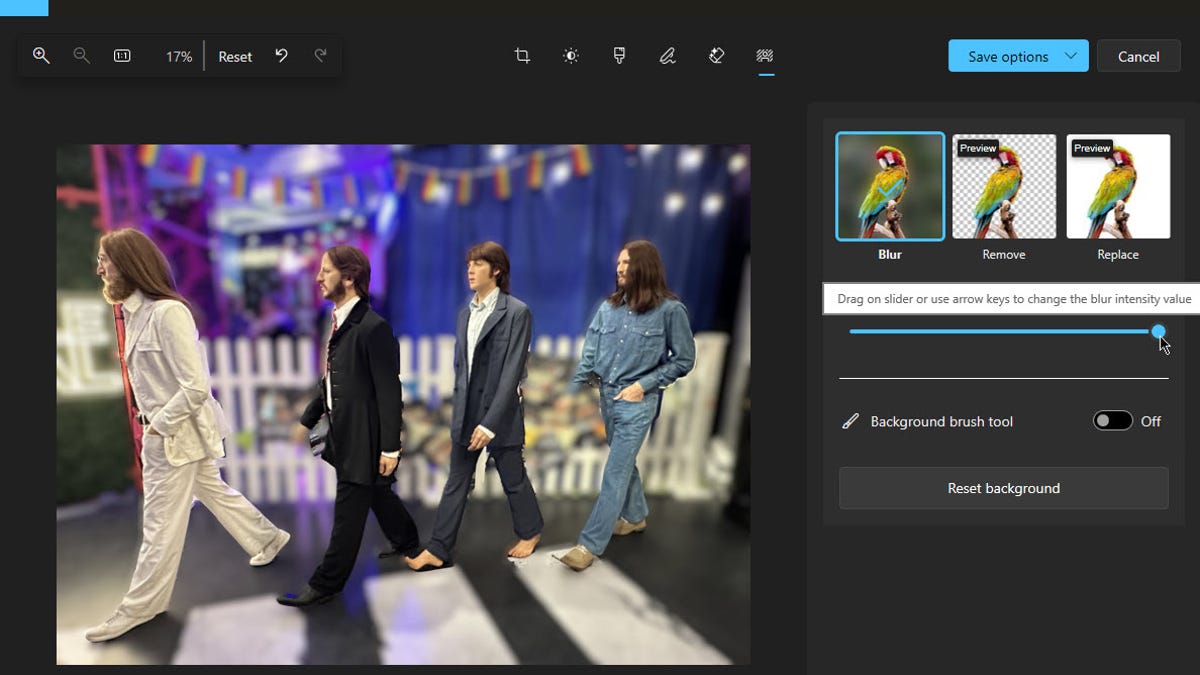
How to use AI in the Windows Photos app to change the background of an image
Screenshot by Lance Whitney/ZDNET You’ve snapped a memorable photo with your phone. There’s only one problem — you don’t like

Chilean instant payments API startup Fintoc raises $7 million to turn Mexico into its main market
Open banking may be a global trend, but implementation is fragmented. The fintech startups doing the legwork to make it
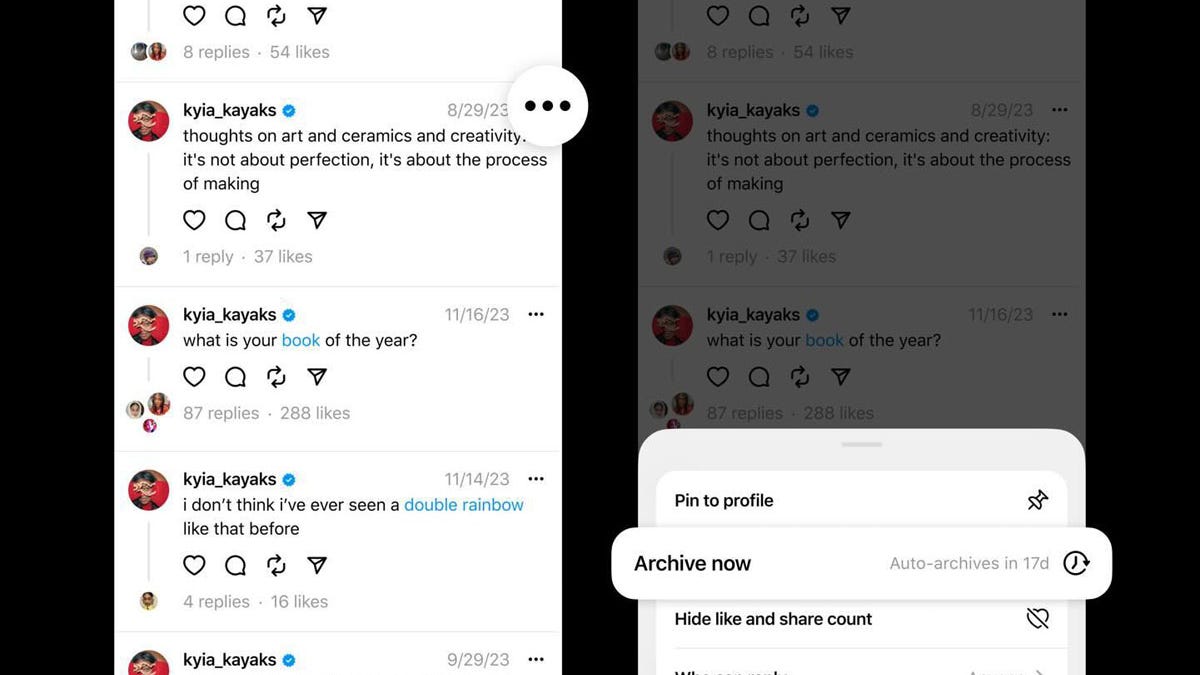
Threads tests letting you hide your public posts, as monthly users jump to over 150 million
Lance Whitney/ZDNET Meta is testing a new Threads feature that lets you archive your public posts, rendering them invisible to
World

Blocks from the White House, US students stand steadfast with Gaza | Israel War on Gaza News
Washington, DC – Chants of “free Palestine” were interrupted by ululating and cheers as dozens of Georgetown University students arrived