

Harry Jowsey is getting candid about his personal health journey. The Too Hot to Handle alum shared that he was diagnosed with
LATEST NEWS



TECHNOLOGY

How Rubrik’s IPO paid off big for Greylock VC Asheem Chandna
When Asheem Chandna drove up to Rubrik’s office in Palo Alto on a Friday night in early 2015, he was

It’s baaack! Microsoft and IBM open source MS-DOS 4.0
Microsoft It’s no joke. Microsoft and IBM have joined forces to open-source the 1988 operating system MS-DOS 4.0 under the
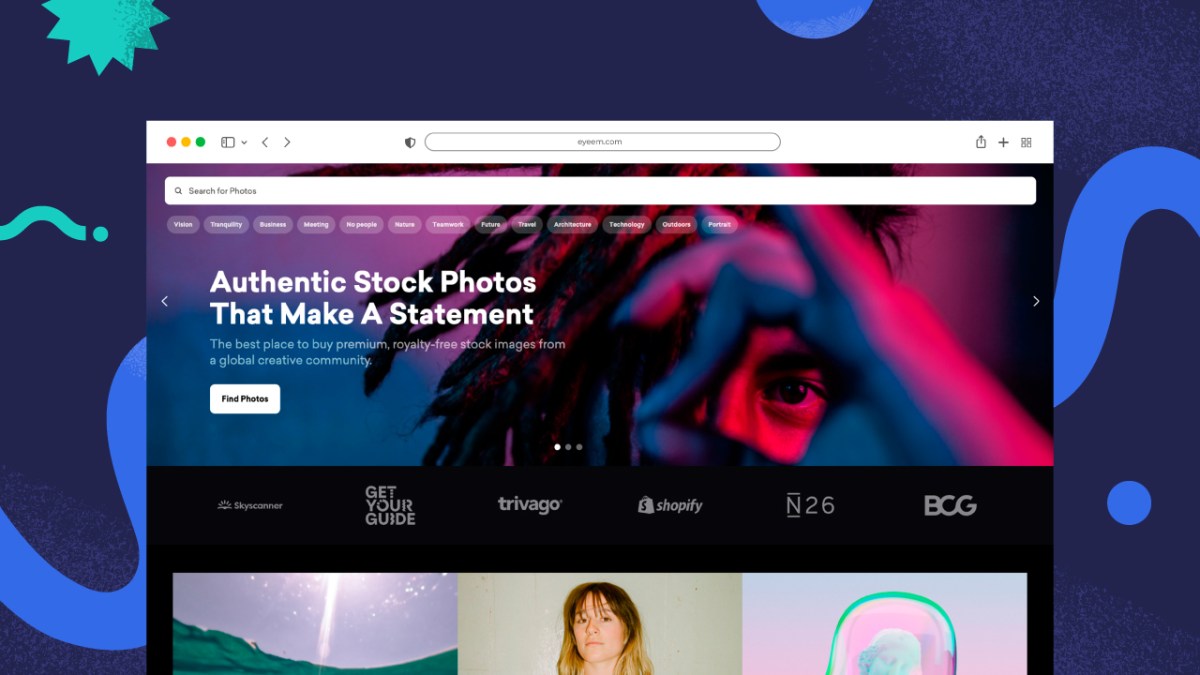
Photo-sharing community EyeEm will license users photos to train AI if they don’t delete them
EyeEm, the Berlin-based photo-sharing community that exited last year to Spanish company Freepik, after going bankrupt, is now licensing its

Overwhelmed? 6 ways to stop small stresses at work from becoming big problems
akinbostanci/Getty Images Modern professionals have busy workloads and juggling all these demands is tough, especially when unexpected challenges appear on

Watch: Between Rabbit’s R1 vs Humane’s Ai Pin, which had the best launch?
After a successful unveiling at CES, Rabbit is letting journalists try out the R1 — a small orange gadget with
World

Generation gap: What student protests say about US politics, Israel support | Israel War on Gaza News
Washington, DC – A Gaza-focused campus protest movement in the United States has highlighted a generational divide on Israel, experts








